A Decade of Demographics in Computing Education Research: A Critical Review of Trends in Collection, Reporting, and Use
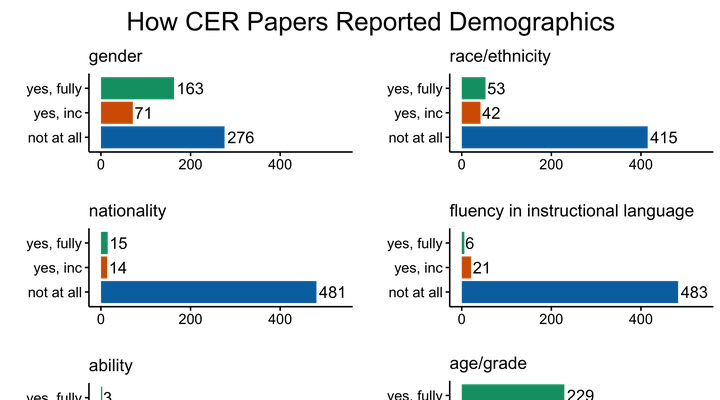 How 510 papers reported demographic attributes (fully, incomplete/partially, not at all).
How 510 papers reported demographic attributes (fully, incomplete/partially, not at all).Abstract
Computing education research (CER) has used demographic data to understand learners’ identities, backgrounds, and contexts for efforts such as culturally-responsive computing. Prior work indicates that failing to elucidate and critically engage with the implicit assumptions of a field can unintentionally reinforce power structures that further marginalize people from non-dominant groups. The goal of this paper is two-fold: to understand what populations CER researchers have studied, and to surface implicit assumptions about how researchers have collected, reported, and used demographic data on these populations. We conducted a content analysis of 510 peer-reviewed papers published in 12 CER venues from 2012 to 2021. We found that (1) 60% of papers studied older learners in formal contexts (i.e. post-secondary education); (2) 68% of papers left unclear how researchers collected demographic data; and (3) while 94% of papers were single-site studies, only 14% addressed the limitations of their contexts. We also identified hegemonic norms through ambiguous aggregate term usage (e.g. underrepresented, diverse) in 23% of papers, and through incomplete reporting of demographics (i.e. leaving out demographics for some participants in their sample) in 35% of papers. We discuss the implications of these findings for the CER field, raising considerations for CER researchers to keep in mind when collecting, reporting, and using demographic data.
ICER ‘22 Activity
At ICER ‘22, we conducted an activity where attendees practiced considering how scenarios reported demographic data and what hegemonic norms these scenarios reinforced. This activity was done collaboratively and documented in Padlet.
Scenario 1 was based on my L@S 2022 paper analyzing Code.org data. Scenario 2 was based on Jean Salac’s ICER 2020 paper on TIP&SEE.